在上一篇《智能运维 | 解放程序员,一个工具就能锁定程序故障》文章中我们主要介绍了一种在服务发生故障时自动排查监控指标的算法。算法的第一步利用了概率统计的方式估算每个指标的异常分数,第二步用聚类的方式把异常模式相近的实例聚集在一起形成摘要,第三步用ranking的方式向工程师推荐最有可能是根因的摘要。

由于运维场景的特点是数据量大,但是标定很少,生成标定的代价高昂而且容易出错,所以我们综合利用了概率统计、非监督学习和监督学习的方法解决问题,在尽量减少训练数据的前提下取得了良好的效果。
在离线实验的70个故障案例中,我们的算法能够把60个案例的根因摘要rank在第一位,显示出了算法强大的生命力。
异常检测算法
异常检测算法是我们整个自动排查监控指标工具的核心,它需要解决跨实例跨指标的异常程度比较问题。这涉及一个本源的问题:什么是异常?
请闭上眼睛想1分钟,再接着往下看。
是不是觉得这个问题似乎不大好回答?作者也拿这个问题为难过不少人。有的人说异常就是不正常呗,但是正常是什么就说不清楚了。有的人说,你给我一些具体的数据我能告诉你哪些是异常,但是脱离具体数据抽象的说不出来。还有人一上来就说,这个问题还真是从来没想过。
正所谓“少见多怪”,说的是因为很少见或者干脆没见过,所以觉得奇怪。又有说“司空见惯”,说的是天天见,所以就习惯了。这两个成语表达的就是不常见的事情容易被看成是怪的,常见的事情就不怪了。换成数学的语言就是:小概率事件是异常,大概率事件是正常。虽然这个说法不是百分之百准确,但是大部分时候还就是这样。所以,衡量指标的异常程度可以用观测到指标值的概率来描述,既然是概率,当然是可以比较的,而且可以跨实例、跨指标地比较。
指标值的观测概率可以从多个不同的角度来建模计算,这里我们主要关注突增突降的情况。指标的突增突降是很容易被人所理解的。比如,工程师们很容易就同意图1中的指标有异常。另一方面,许多故障都会体现在某些指标的突增突降上。最关键的是,计算指标的突增突降对应的观测概率是比较容易的,很适合我们这种需要扫描大量指标的场景。
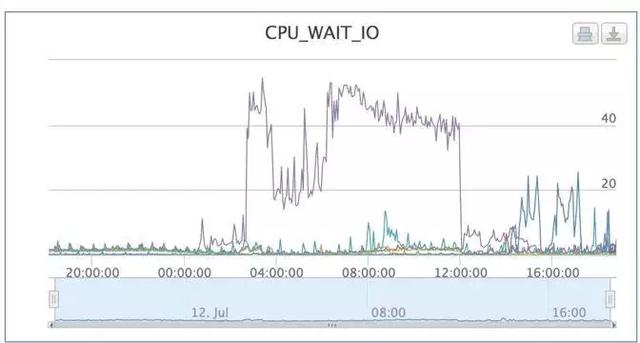
图1 CPU_WAIT_IO的突增说明出现了磁盘竞争

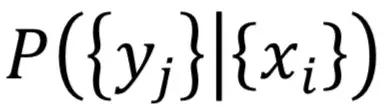

上溢概率:
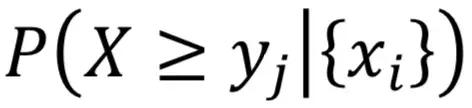
下溢概率:
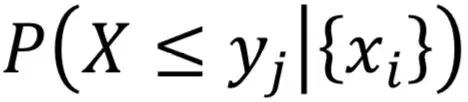

上溢概率:
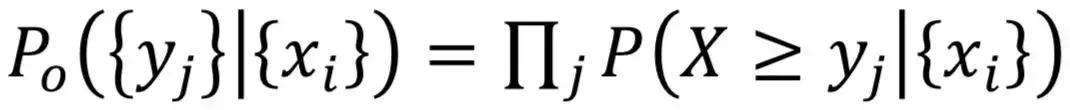
下溢概率:
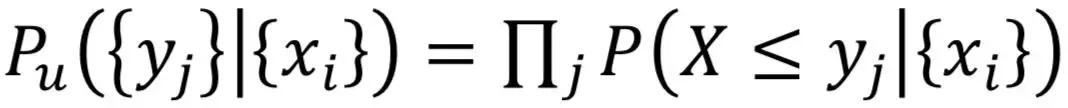
为了方便计算和人的查看,通常会计算概率的对数。概率的对数都是负数,大家看正数比较自然,所以我们就把概率的对数的负数作为异常分数
上溢分数:
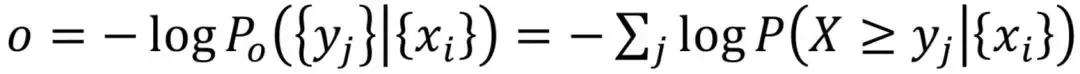
下溢分数:
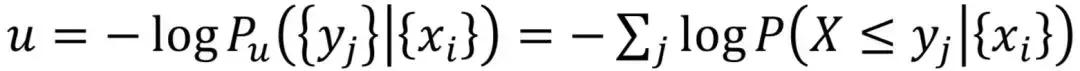

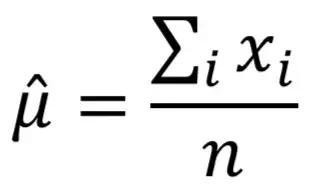


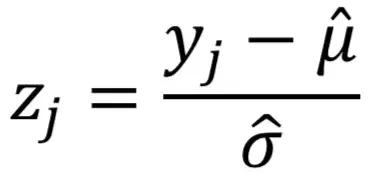

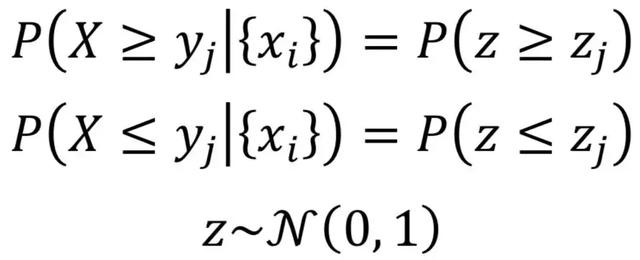

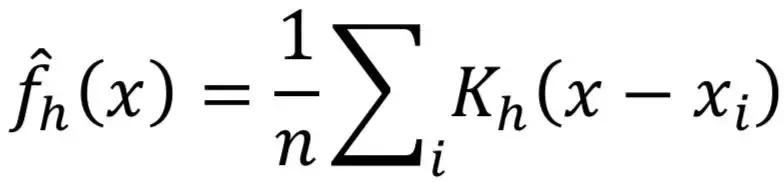

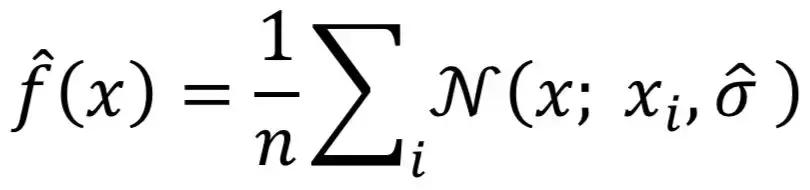
对于像CPU_IDLE一样的指标,我们可以用Beta分布作为核函数,这时
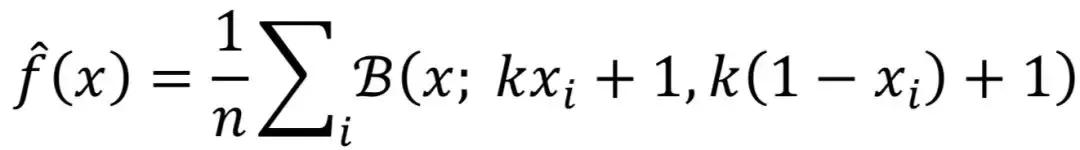

有了概率密度函数,单点的概率就可以利用积分计算了

聚类
在为每个指标计算异常分数之后,我们把属于同一个实例的指标的异常分数合起来,形成一个异常分数的向量
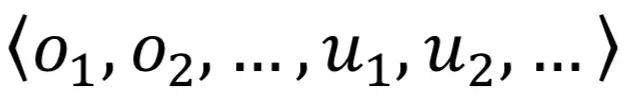
这里的每一个下标对应一个指标。
为了便于工程师阅读,我们需要把异常模式差不多的向量通过聚类的方法聚在一起。聚类是无监督学习(Unsupervised Learning)的典型方法之一。与监督式学习(SupervisedLearning)不同,聚类不能通过样本的标记(Label)来控制输出的结果,所以控制聚类方向的核心就落在了距离函数和聚类算法上。

在聚类算法上,由于我们事先无法知道有多少种不同的异常模式存在,K-means显然就不是一个很好的选择了。层次聚类和DBSCAN都不需要预先设定聚类的个数,能更好地适应我们的需求。在实验中,我们采用了DBSCAN,确实得到了很好的效果。
聚类时,理论上我们可以把所有模块的所有实例放在一起聚类。在实验中我们发现这样的聚类结果有时候也还可以,而且它可以发现跨模块的问题,比如由于网络故障导致多个模块之间通信收到影响最终产生整个系统的故障。但是,这种方法也在不少情况下的输出并不好。所以,我们采用了相对保守的方式,将聚类局限在属于同一个模块、同一个机房的实例中。
排序(Ranking)
聚类算法把异常模式相似的实例聚到了一起,形成摘要。每个摘要已经具备一定的可读性,我们只需要把属于根因模块的摘要排在前面推荐给工程师就大功告成了。
排序算法考虑的因素有以下三个:
1. 摘要中实例的个数,实例越多说明影响越大,就越有可能是根因。
2. 摘要中异常分数特别高的指标的个数,指标越多越可能是根因。
3. 摘要中各实例指标的平均异常分数,平均分数越高越可能是根因。
将以上三个因素的值计算出来,就形成了三个feature。我们只需要用通常的方法训练一个ranker就可以了。
表格 1 中是错误!未找到引用源。 所示的那个故障案例的自动分析结果。
标中的第一列是摘要所属的模块与机房。
第二列是摘要中实例在同模块同机房的实例中所占的比例。
第三列是摘要中的实例列表。
第四列是异常分数特别高的指标以及它们的异常分数。
我们的算法确实把根因模块G中的一个摘要最为第一个推荐出来了。通过第四列的内容,我们可以看出机房DC1中的G模块因为某种原因超载了。G超载后,它对上游模块的响应变慢,从而使得同机房中的E模块不得不维护更多的RPC连接,所以同机房的E模块被拍在了第二位,而且与网络连接数相关的指标也确实出现了异常。
表1 故障的排查分析结果

总 结
故障诊断作为智能运维中的一个典型的复杂场景,一直是众多运维工程师的努力方向。本文介绍的指标自动排查算法表明,除了机器学习之外,概率统计也将会在智能运维中占据重要的位置。
关于故障诊断的研究,如有任何想法和疑问,欢迎留言一起交流。
')}
