在此前介绍百度云智能运维(Noah)外网质量监测平台文章《百亿级外网访问质量保障:百度猎鹰外网监控(上)》中,我们简要介绍了一种网络异常类型——机房侧异常(百度数据中心侧设备/链路异常)。该故障在数据上表现为多个省份访问某个百度机房服务不通畅,因此在猎鹰(百度外网监控平台)外网判障中,可以通过设置访问某机房出现异常的省份比例超过给定阈值,来判定机房侧异常的发生。
在外网故障统计中我们发现,运营商骨干网链路出现故障同样会导致多个省份到特定机房访问异常,在现有外网判障框架中,会将骨干网链路异常也判定为机房侧异常。然而,机房侧异常与骨干网链路异常无论是从起因还是数据表现上,都是存在一定差异的,两者的止损方式也不相同。因此,我们需要设计判障策略来区分两类异常,以便自动止损系统根据异常类型执行合适的外网止损方案。
在下文中,我们将为大家介绍骨干网链路及其异常表现,以及判障策略的设计思路。
什么是骨干网链路?
骨干网是运营商用来连接多个地域或地区的高速网络,因此骨干网的一个重要作用就是承载跨地域传输的网络数据。若干条跨地域连接的骨干网链路,共同组成了完整的运营商骨干网。
图1所示是用于连接南北地域的一条骨干网链路——第二京汉广链路。各省份跨南北地域传输的网络数据,首先会汇聚到该链路上北京、武汉、广州等核心城市节点,然后经由该链路传输至目的位置。
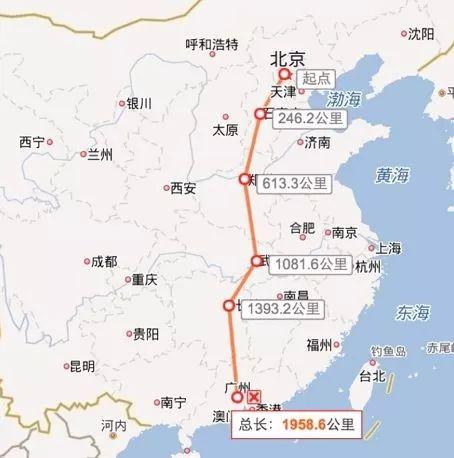
图1 第二京汉广链路
当构成这条骨干网链路的网络设备,如交换机、光纤等,出现拥塞、损毁等异常状况时,流经链路故障位置的网络数据会受到影响,通常表现为丢包甚至数据断连。
骨干网异常对百度外网质量的影响
如图2所示,外网监控系统猎鹰通过在各省份的探测点,实时监控百度各机房的网络连通性状态。
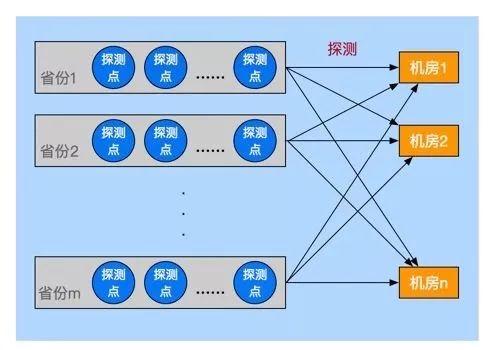
图2 猎鹰外网监控图示
在每个判定周期,每个省份都会上报若干条对百度各机房的探测数据。假设某省份对特定机房的探测,共上报了m条数据,其中n条数据为异常状态,那么异常率n/m可以用于衡量省份到机房的外网质量。
骨干网链路发生异常时,会使得百度外网质量受损。具体表现为:用户跨地域访问百度机房时异常率升高,而用户访问同地域的百度机房服务时异常率不受影响。
图3(a)(b)分别展示了某次南北骨干网链路异常发生时,全国各省份访问百度南北两地机房的异常率。其中,不同省份颜色对应的异常率如图中左下角所示。
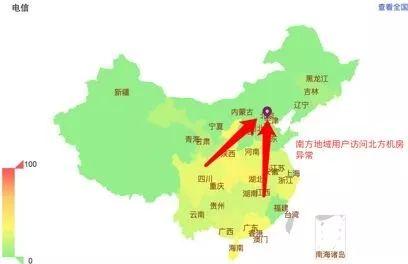
图3(a) 南北链路异常发生时,全国访问北京机房异常率

图3(b) 南北链路异常发生时,全国访问广州机房异常率
从图3(a)中可以看出,河南-山东线以南的省份,访问百度北京机房普遍出现异常率升高,而以北的省份访问北京机房异常率则较低。图3(b)中各省份访问广州机房也出现了跨南北地域访问异常、同地域访问正常的情况。
骨干网异常与机房侧异常的区别
图4展示了机房侧异常发生时的各省份网络异常率。对比图3和图4可以看出,连接两个地域的骨干网链路异常发生时,异常省份通常聚集于同一地域,并且各省份都会出现访问跨地域的机房异常,访问同地域的机房正常的现象。而机房侧异常发生时,异常省份会分散于全国各地,没有明显的分布规律。这个差异是区分两类异常的关键所在。

图4 机房侧异常发生时,全国访问异常机房的异常率
由于两类异常表现不同,因此对应的止损方案也存在差异。对于机房侧异常,可以直接将异常机房的所有流量全部调度至正常机房。而对于骨干网链路异常,由于异常只在跨地域访问时发生,因此需要处理所有跨地域访问流量,可以将所有跨地域的访问流量调度至同地域正常机房。为了使自动止损系统能对骨干网异常执行合适的外网止损方案,为骨干网链路异常设计判障策略是有必要的。
另外,由于运营商的骨干网拓扑主要连接的是南北向各核心城市,骨干网异常也都发生在南北向骨干网链路上,因此后续的策略设计都将围绕南北骨干网链路(下文简称南北链路)展开。
判障思路分析
根据南北链路异常的特点以及问题的性质,我们尝试从以下两个思路来考虑解决方案。
- 基于南北划分线进行判定
南北链路异常最显著的特点,就是跨地域访问机房异常率高、同地域访问异常率低,且高异常率与低异常率省份间存在明显的南北划分。根据这个特点,一个直观的想法就是根据历史数据总结出一条南北划分线;通过观察划分线两侧省份异常状况,从而确定异常类型。
然而,通过观察历史上多次南北链路异常我们发现,划分线没有固定的位置。它是随着骨干网链路异常的位置动态变化的,根据划分界线位置的变化,异常省份也存在着差异。如下图所示,(a)与(b)分别是异常链路存在于河北、河南境内时,用户访问百度北京机房的异常率展示。
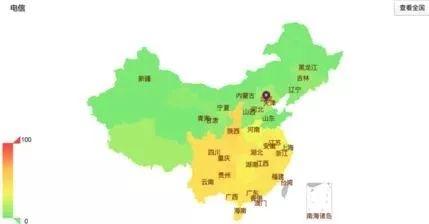
图5(a) 河北境内链路故障
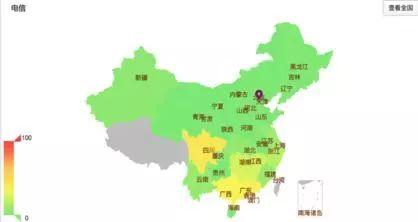
图5(b) 河南境内链路故障
从图5(a)可以看出,当异常链路位于河北时,河北以南的省份,访问北京机房异常率普遍较高,即划分线位于河北-山东线附近。而图5(b)异常链路位于河南时,划分线纬度则下移至陕西-河南线以下,该线以南的省份异常率较高,异常省份个数也由于划分线位置下移而少于(a)图。
因此,找到一个合适的南北分界线,观察分界线两边省份的异常状态,来判定是否有南北链路异常发生,这个想法难以直接落地。
- 利用分类器模型进行判定
如概览中所说,我们希望对已经判定为机房侧异常的数据做二次处理,正确将机房侧异常与南北链路异常区分开来。显然,这是一个二分类问题,利用分类器模型解决也是一个思路。
如果在每个判定周期,都能获得大陆31个省份到各机房的探测数据,那么可以通过积累历史数据,训练一个接受62维特征数据(南北两地机房各自对应的31个省份异常状态)的分类器,用于区分南北链路异常和机房侧异常。
然而由于探测数据回传延迟、回传链路故障、单省份探测点少等原因,难以保证每个判定周期都能拿到31个省份到机房的完整探测数据,即特征数据大概率存在缺失值。另外南北链路故障发生次数较少,可用于训练分类器的数据样本不足,训练出的模型极易过拟合。
根据对这两个思路的分析,可以发现它们由于存在一些问题而难以直接应用。因此,我们综合了这两个思路中有用的部分,设计了骨干网判障策略。
骨干网异常判定策略
综合考虑上述两个方案,我们尝试在判障策略中采用分类器模型,并人为设计特征来减少特征维度,减少模型过拟合的风险。
判障策略的具体步骤如下:
- 确定省份异常状态真值
我们根据各省份异常率以及人为设定的阈值,判定该省份到机房的异常状态,并且以此状态作为省份异常状态的真值。
- 寻找划分线位置
在判定各省份到某机房的异常状态后,对所有省份按照纬度进行排序,并将每个省份都作为可能的划分位置进行遍历,寻找使得“划分误差”最小的位置,作为划分线位置。
每个可能划分位置都会将省份集合分为划分位置以南的集合与划分位置以北的集合。根据南北链路异常的特点可知,若异常机房为南方机房,则应为正常省份的集合,而应为异常省份的集合。若异常机房为北方机房,则为相反情况。
对于每个省份,若由划分得到的省份状态与省份异常状态真值不符,则认为该省份被划分错误,划分误差可以通过划分错误的省份数/总省份数得到。
如图6示例,假设8个省份被划分,且上半部分为正常省份集合,下半部分为异常省份集合。根据异常状态真值,可计算得到划分误差为2/8=0.25。
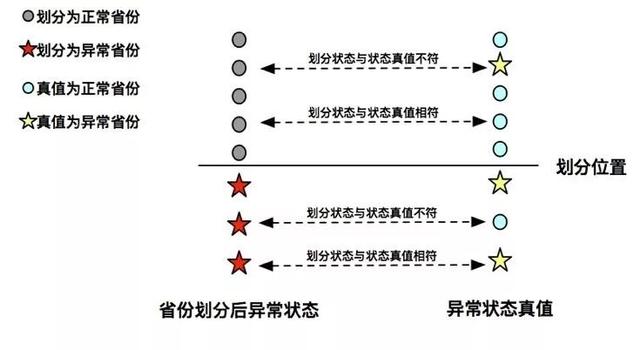
图6 划分误差计算示例
在遍历所有可划分位置后,即可得到最小划分误差及对应的划分位置了。
- 特征提取
根据对历史数据的观察得知,南北链路异常对应的划分误差相对较小,且划分线在地图中部位置上下变化。而机房侧异常划分位置和误差没有规律可循。图7展示了两类异常数据的散点图。
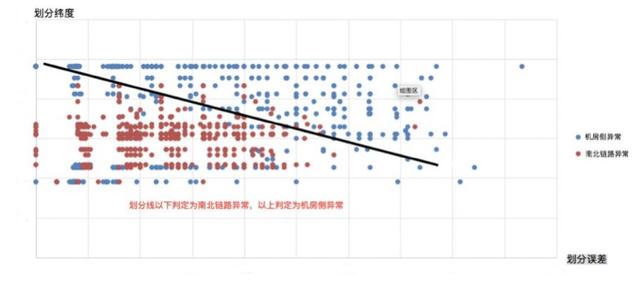
图7(a) 线性划分结果
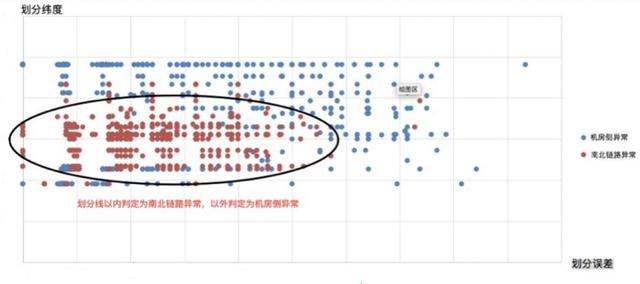
图7(b) 非线性划分结果
从图7(a)与(b)可以看出,仅使用两维特征的情况下,无论是线性分类还是非线性分类,都很难将两类异常数据较好地划分开来。
为了提高分类效果,我们需要引入其他辅助分类的特征,具体如下:
- 机房位置、异常省份纬度中位数
两者的相对位置关系在南北链路异常时具有明显特征,因此这两维数据的引入增强了南北链路异常的可识别性。例如,南北链路异常发生时,到南方机房异常的省份通常在纬度上远大于机房所在的广东省。取中位数为了消除极端点和噪声带来的影响。
- 划分位置两边省份异常率均值
机房侧异常发生时,异常省份的分布通常是较为均匀分布于全国各地,因此划分线两边省份的异常率均值差距通常不会很大。因此这两维特征有助于分类器识别机房侧异常。
- 分类器训练
为了区分两类异常类型,我们将训练一个二分类器,训练数据正例为南北链路异常按上述步骤提取到的特征,反例为对机房侧异常提取的特征。在分类器的选取上,我们选择了支持向量机(SVM)这一常用的分类器模型,并根据实验回溯效果选择了合适的核函数。通过以上步骤,我们实现了骨干网链路异常的判定策略。自上线运行以来,取得了极佳的异常判定效果。
总 结
本文从外网异常监控遇到的实际问题出发,介绍了骨干网链路异常以及判定策略的设计思路。该策略有效地解决了骨干网异常与机房侧异常混淆的问题,使得百度云智能运维产品Noah能够精确定位骨干网链路异常,完善监测能力。
')}
